-
Usługi i
rozwiązania Usługi i rozwiązania
Usługi i rozwiązania -
Produkty
Usługi i rozwiązania
-
Partnerzy
technologiczni -
Baza wiedzy
Usługi i rozwiązania
Deduplikacja danych – jak optymalizować przestrzeń dyskową i oszczędzać zasoby?
W dobie cyfryzacji każda sekunda generuje olbrzymią ilość danych. Zarówno użytkownicy indywidualni, jak i przedsiębiorstwa nieustannie tworzą nowe pliki, przechowują informacje i dokonują transferów danych. Jak zatem efektywnie zarządzać tym lawinowo rosnącym strumieniem informacji? Z pomocą przychodzi deduplikacja danych – technologia, która może zrewolucjonizować sposób, w jaki przechowujemy i zarządzamy informacjami.

Co to jest deduplikacja danych?
Deduplikacja to proces eliminowania powielonych fragmentów informacji, aby zmniejszyć objętość przechowywanych danych. Innymi słowy, jeśli w naszym systemie znajdzie się kilkukrotnie ta sama kopia pliku, deduplikacja zadba o to, aby pozostawić tylko jedną unikalną wersję, a resztę zamienić na odpowiednie wskaźniki. Dzięki temu technika ta pozwala znacznie zredukować zużycie przestrzeni dyskowej i zasobów systemowych.
Deduplikacja może odbywać się na trzech poziomach:
- Deduplikacja na poziomie plików: Usuwa identyczne kopie plików, co jest idealnym rozwiązaniem dla prostych systemów zarządzania danymi.
- Deduplikacja na poziomie bloków: Idzie o krok dalej, analizując mniejsze fragmenty danych (bloki), nawet jeśli znajdują się one w różnych plikach.
- Deduplikacja globalna: To najbardziej zaawansowana forma, optymalizująca dane na poziomie całej infrastruktury, niezależnie od miejsca ich przechowywania.
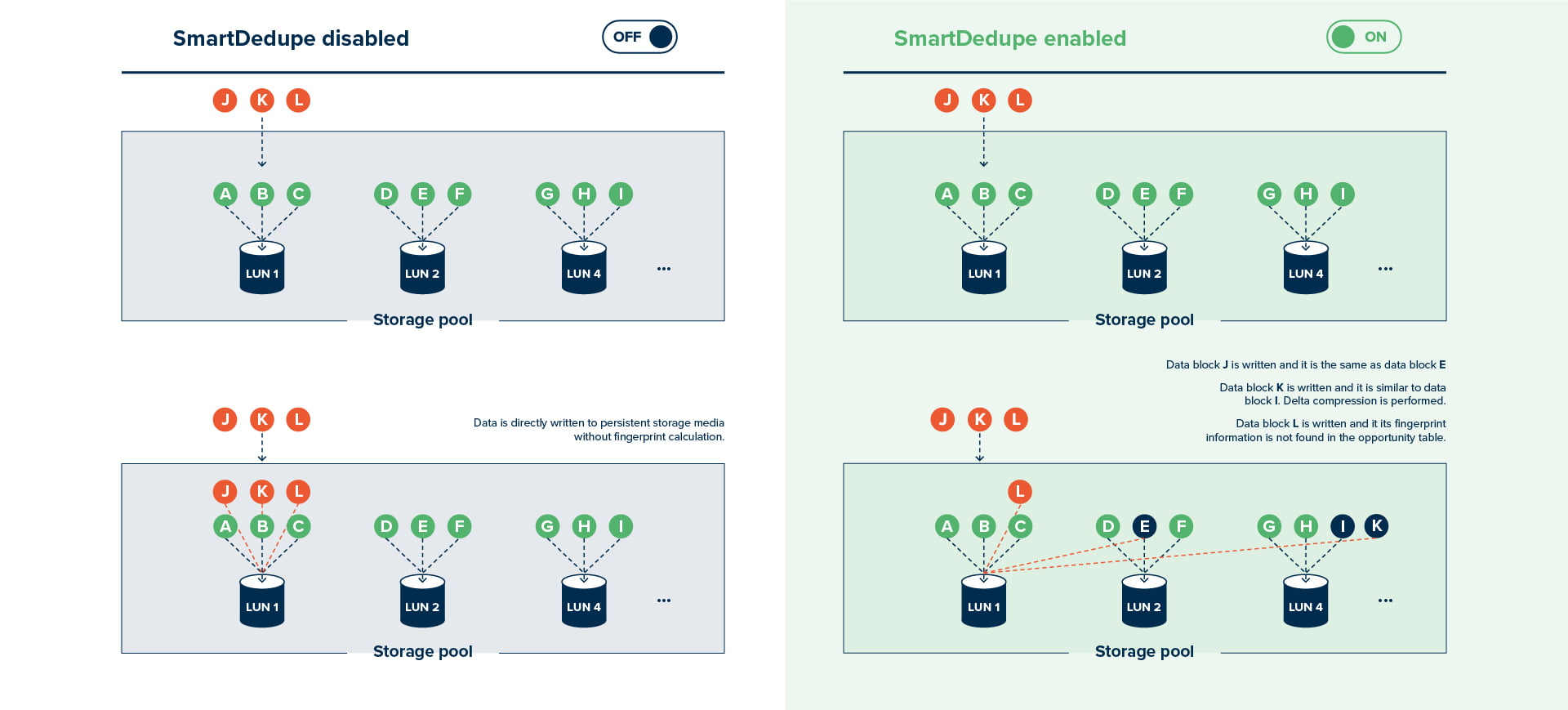 Źródło: Huawei
Źródło: Huawei
Jak działa deduplikacja?
Proces deduplikacji można podzielić na kilka etapów:
- Identyfikacja duplikatów: Algorytmy analizują dane, poszukując powtarzających się fragmentów.
- Tworzenie odnośników: Zamiast przechowywać zduplikowane dane, system tworzy odwołania do unikalnej kopii.
- Kompresja i zapis: Zredukowane dane są kompresowane i zapisywane, co pozwala jeszcze bardziej zmniejszyć objętość przechowywanych informacji.
Dlaczego deduplikacja jest tak ważna?
Oszczędność przestrzeni dyskowej jest kluczowa w świecie, gdzie każdy dzień generuje terabajty nowych danych, a deduplikacja staje się nieoceniona. Dzięki niej możemy znacznie zmniejszyć ilość miejsca potrzebnego do przechowywania plików, co z kolei wydłuża żywotność infrastruktury i obniża koszty związane z jej utrzymaniem. Redukcja kosztów operacyjnych jest kolejnym ważnym aspektem, gdyż mniejsze zasoby dyskowe to niższe koszty operacyjne, a także mniej czasu poświęcanego na backupy, archiwizację i odzyskiwanie danych. Zwiększenie wydajności sieci to również istotna korzyść, ponieważ dzięki optymalizacji przepływu danych deduplikacja zmniejsza obciążenie sieci, co skutkuje szybszym przesyłaniem plików i lepszą wydajnością systemów IT.
Najnowsze trendy w deduplikacji
W miarę rozwoju technologii deduplikacja ewoluuje, dostosowując się do nowych wyzwań i potrzeb. Deduplikacja w chmurze staje się coraz bardziej popularna, gdyż coraz więcej firm przenosi swoje zasoby do chmury, co sprawia, że deduplikacja staje się kluczowym narzędziem do zarządzania przestrzenią dyskową w takich środowiskach. Amazon S3, Microsoft Azure czy Google Cloud oferują wbudowane mechanizmy deduplikacji, co pozwala na efektywne zarządzanie kopiami zapasowymi i szybkie odzyskiwanie danych w razie awarii.
Deduplikacja w czasie rzeczywistym to kolejny trend, gdzie tradycyjnie deduplikacja odbywała się po zapisaniu danych na dysk, a teraz coraz więcej rozwiązań wprowadza deduplikację w czasie rzeczywistym, eliminując duplikaty już w momencie tworzenia lub przesyłania danych.
Deduplikacja z wykorzystaniem AI i ML (Machine Learning) to innowacyjne podejście, gdzie algorytmy sztucznej inteligencji i uczenia maszynowego rewolucjonizują deduplikację, umożliwiając bardziej zaawansowaną analizę danych. Systemy oparte na AI mogą identyfikować nie tylko dokładne kopie, ale również podobieństwa między danymi, co pozwala na jeszcze większe oszczędności.
Deduplikacja w kontekście IoT staje się coraz ważniejsza, ponieważ Internet Rzeczy generuje ogromne ilości powtarzających się danych, takich jak logi z sensorów, a deduplikacja pozwala efektywnie zarządzać tymi informacjami, co jest kluczowe dla sprawnego działania systemów IoT.
Zastosowania deduplikacji w różnych branżach
Deduplikacja znajduje szerokie zastosowanie w różnych sektorach, przynosząc wymierne korzyści. W sektorze finansów i bankowości zarządzanie danymi klientów, transakcjami i kopiami zapasowymi staje się znacznie prostsze, a koszty przechowywania danych spadają. W służbie zdrowia deduplikacja pomaga zredukować ilość miejsca potrzebnego do archiwizacji dokumentacji medycznej i obrazów diagnostycznych. Branża IT, w tym firmy zajmujące się tworzeniem oprogramowania i zarządzaniem danymi, może lepiej zarządzać zasobami dzięki deduplikacji, co prowadzi do zwiększenia wydajności operacyjnej.
Podsumowanie
Deduplikacja to nie tylko technologia redukcji danych, ale także narzędzie, które pozwala firmom oszczędzać miejsce, zasoby i pieniądze. W czasach rosnącej liczby danych i dynamicznego rozwoju technologii, deduplikacja staje się jednym z kluczowych elementów optymalizacji systemów IT.
Jeśli Twoja firma jeszcze nie korzysta z deduplikacji, teraz jest najlepszy moment, aby rozważyć wdrożenie tej technologii. Skontaktuj się z naszymi ekspertami, aby dowiedzieć się, jak możemy pomóc zoptymalizować Twoje zasoby i wprowadzić innowacyjne rozwiązania deduplikacyjne do Twojego biznesu!


![Huawei Datacenter Virtualization Solution – nowy standard w wirtualizacji? [case study]](https://vectortechsolutions.com/wp-content/uploads/2024/09/VTS-obrazek-wyrozniajacy-pod-artykul-1.png)
